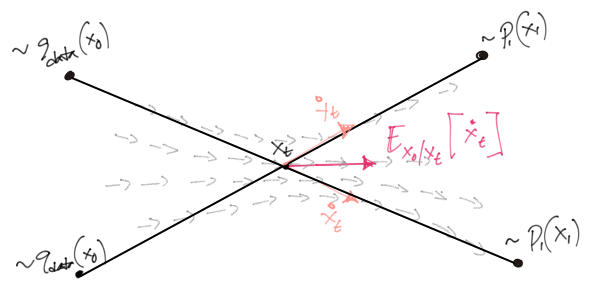
Match flows, not scores
Deep Learning
Generative Models
Diffusion
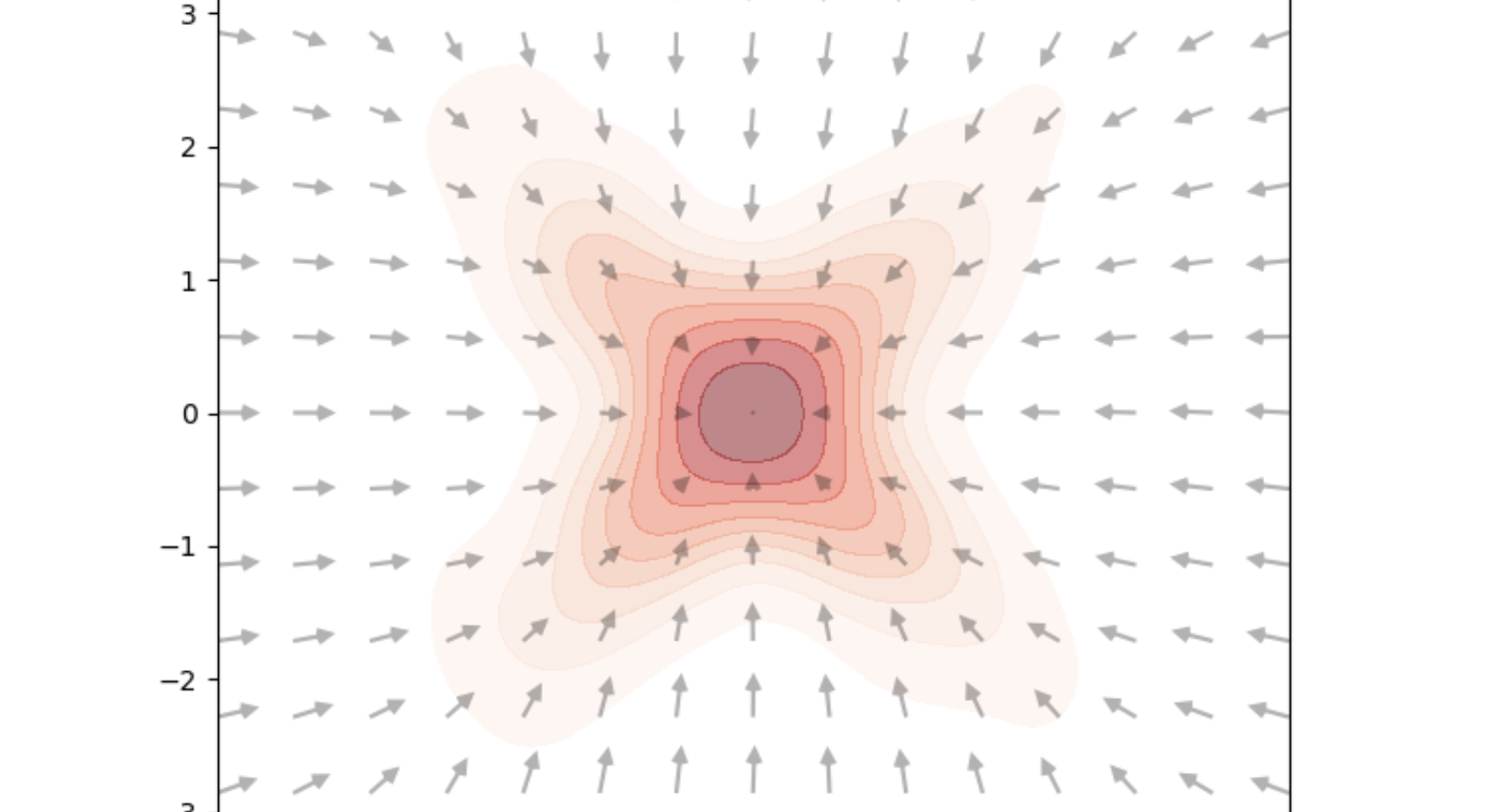
Building Diffusion Model’s theory from ground up
Deep Learning
Generative Models
Diffusion
Differential Equation
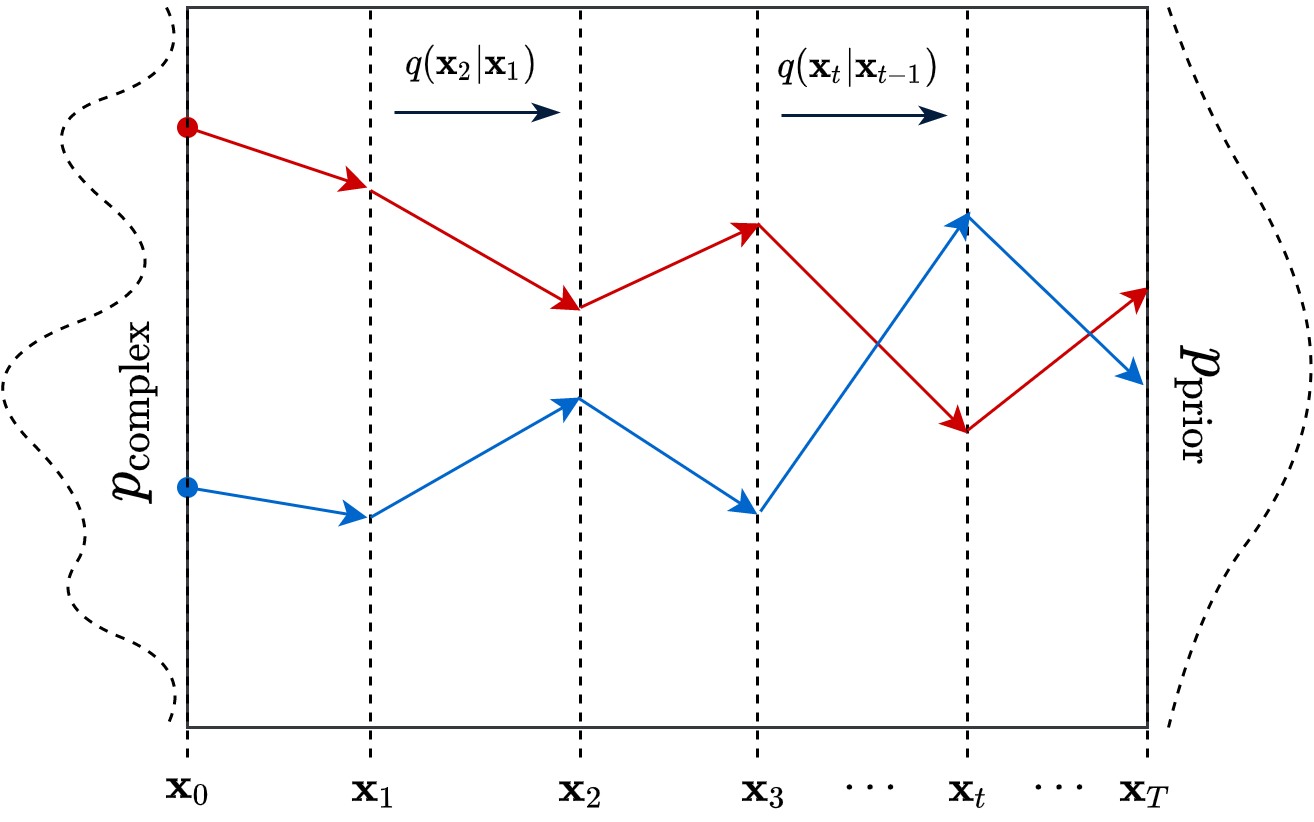
An introduction to Diffusion Probabilistic Models
Deep Learning
Generative Models
Diffusion

Generative modelling with Score Functions
Deep Learning
Generative Models
Diffusion
Energy based models
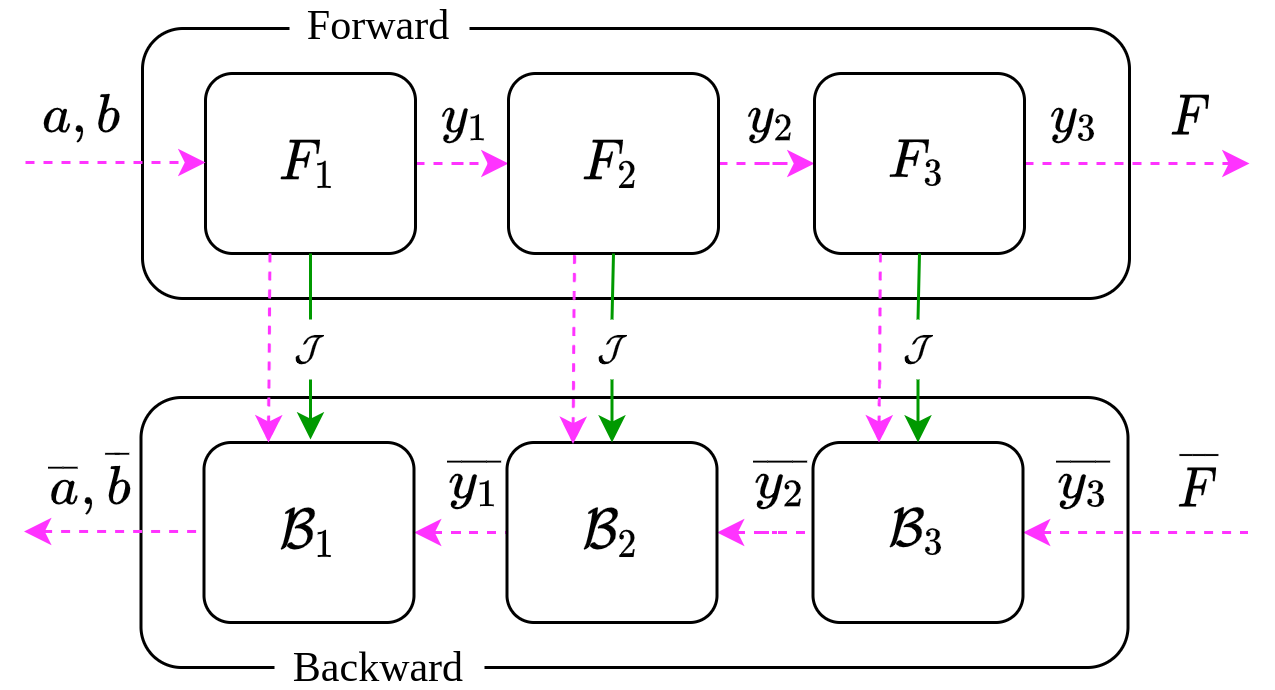
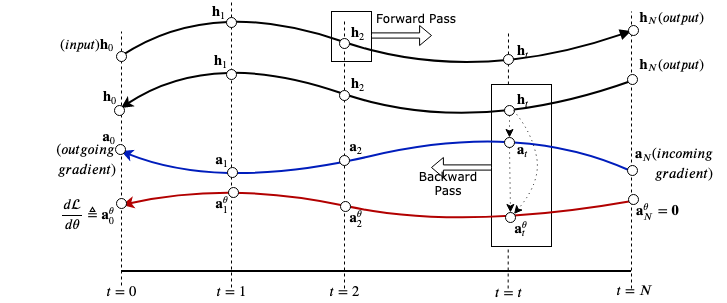
Differentiable Programming: Computing source-code derivatives
Compilers/Interpreter
Deep Learning
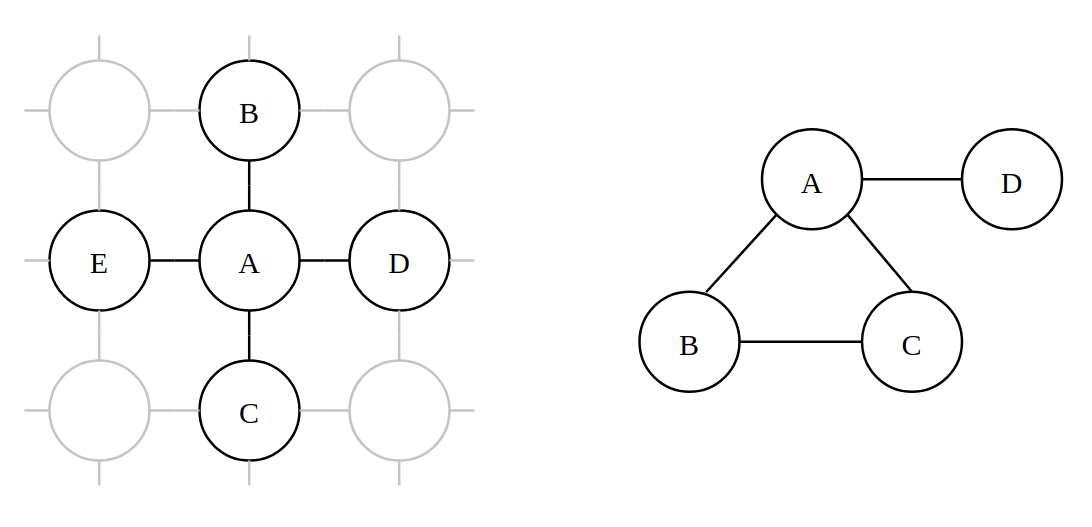
Introduction to Probabilistic Programming
Graphical Models
Deep Learning
Variational Methods
Generative Models
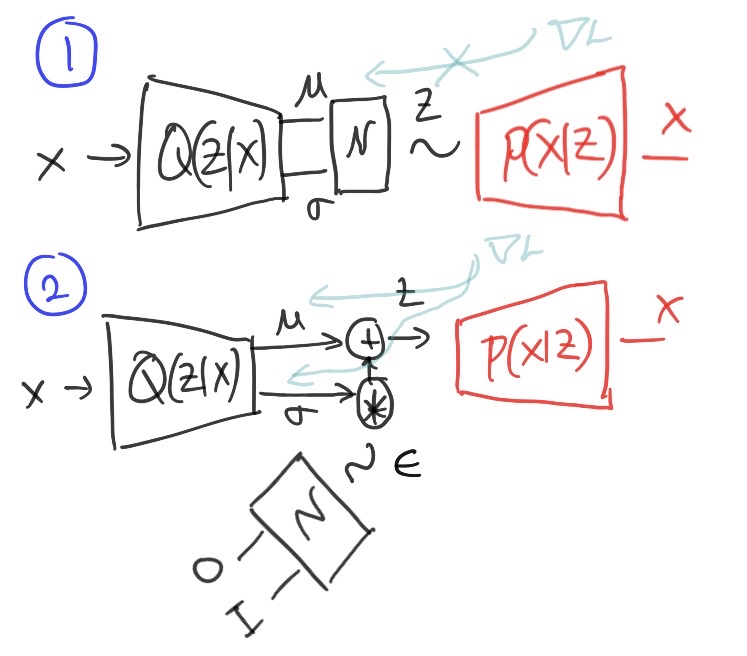
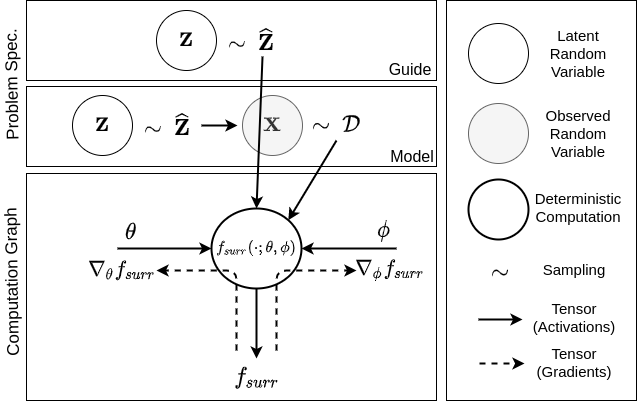
Foundation of Variational Autoencoder (VAE)
Deep Learning
Variational Methods
Graphical Models
Generative Models
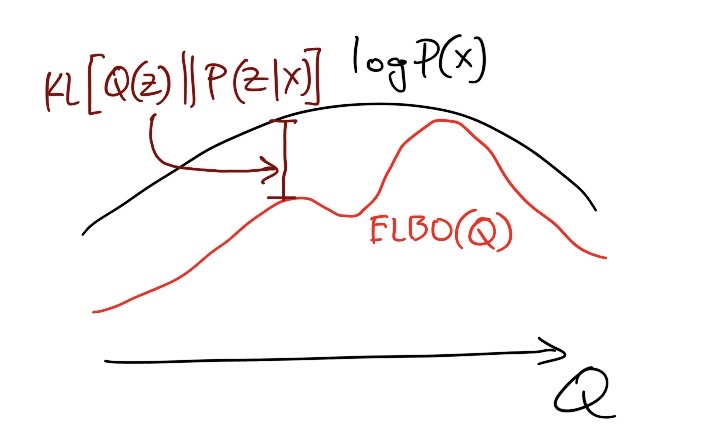
Directed Graphical Models & Variational Inference
Variational Methods
Graphical Models
Deep Learning

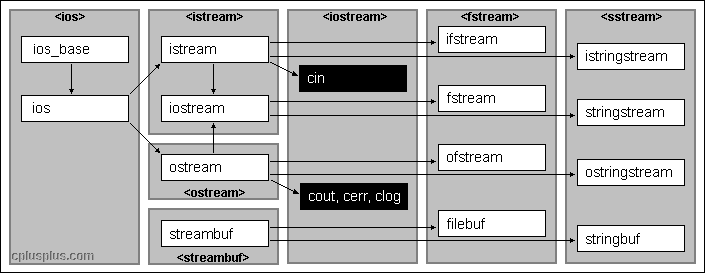
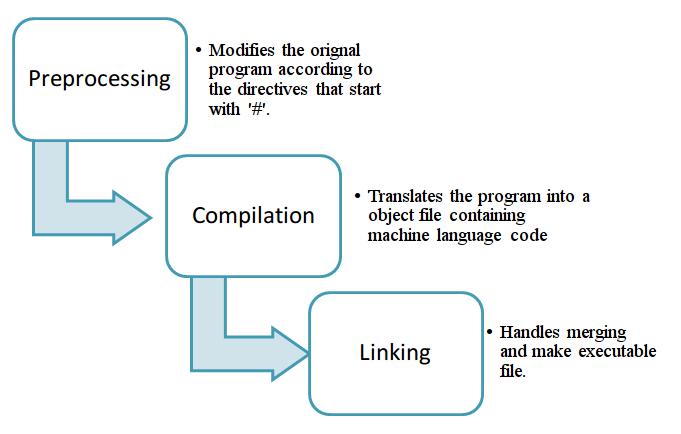
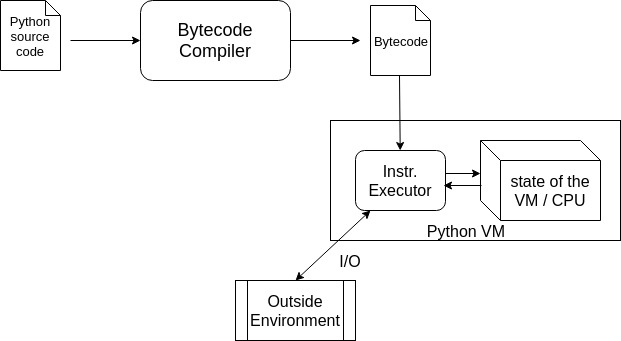
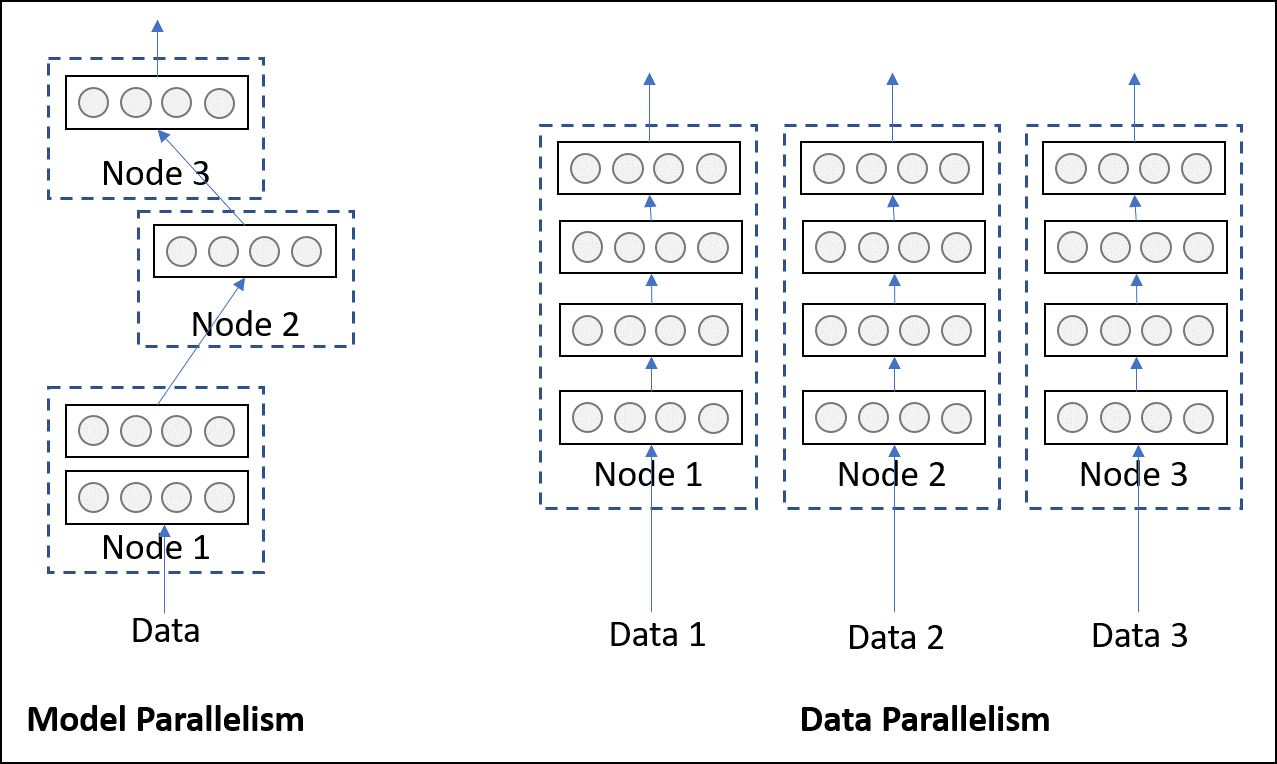
Deep Learning at scale: The “torch.distributed” API
Distributed Computing
Deep Learning
Deep Learning at scale: Setting up distributed cluster
Distributed Computing
Deep Learning

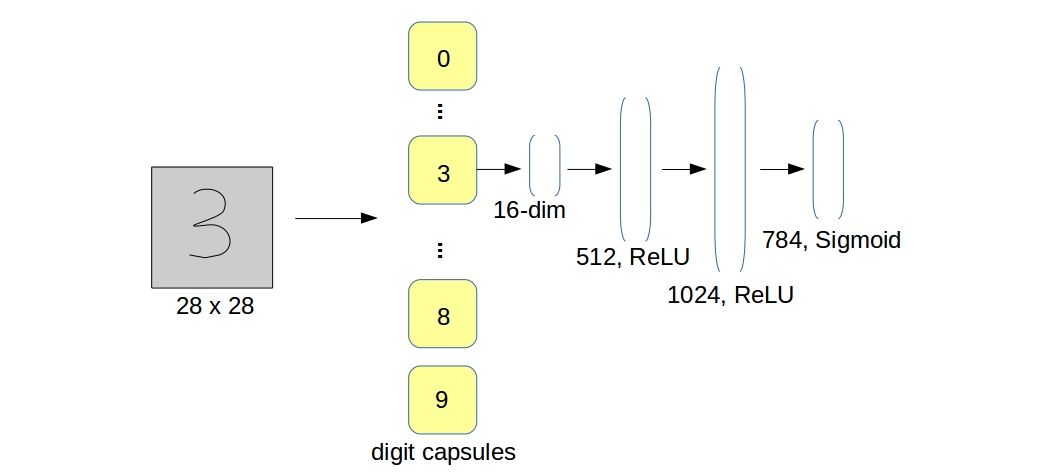
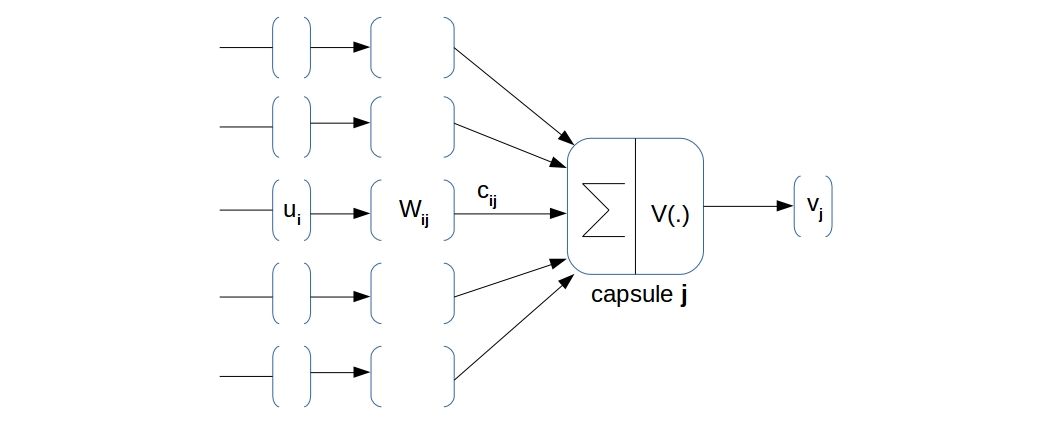
No matching items